您现在的位置是:首页 > PHP > 【采集网页篇】,php有专门的类库 网站首页 PHP
【采集网页篇】,php有专门的类库
简介
暂无
这段时间一直在抓取网页,用了多了发现正则表达式也不是那么好写,动不动就写不出来了,但是用多了页找到了一些用些抓取的类库,比如phpquery,和querylist,用起来怎么说呢,想使用jquery操作一样简单
这里重点介绍使用querylist3.0,我的php版本是5.6,querylist4.0需要php版本7.0,那就没办法了
querylist:
- 去querylist官网下载两个文件(或者本文末尾,小主也会附上地址),phpquery.php 和querylist.php这两个类库,(啰嗦一点就是,querylist也是基于phpquery的抓取方面提升的类库,其实phpquery还可以做其他的功能,比如。。。。)
- 然后就是放在项目中,引用两个文件就可以了,然后在文件开头使用命名空间 use QL\QueryList;
- 接下来就是使用了,最主要的就是传入规则,
- 然后可以针对性的对每一条规则传入回调处理方法
具体方法:
- require JD_GEN_PATH.'extend/phpquery/phpQuery.php';
- require JD_GEN_PATH.'extend/phpquery/QueryList.php';
- $hj = QueryList::Query('http://www.baidu.com',
- array(
- "url"=>array('div a','href'),//绿色的内容表示:找到div下面的a标签的href的值
- "book_name"=>array('div a','text'),//这里的蓝色表示可以是任意属性,比如href,html,src等
- "author"=>array('.result-game-item .result-game-item-info p:contains("作者:")','text','',function($res){
- //回调中可以使用php的所有语法,比如针对多余的数据,去空格,替换字符等
- $book_author = str_replace("作者:","",$res);
- $book_author = trim($book_author);
- return $book_author;
- }),
- ));
- $data = $hj->getData(function($x){
- return $x;//返回的结果是以多维数组的方式放回
- });
- _success($data);
下面放上两个类库的下载地址,I Am Address Click Me!
最近在做一个自己的小说阅读器,所以采集用的很多,放两张low图;仪式:纪念
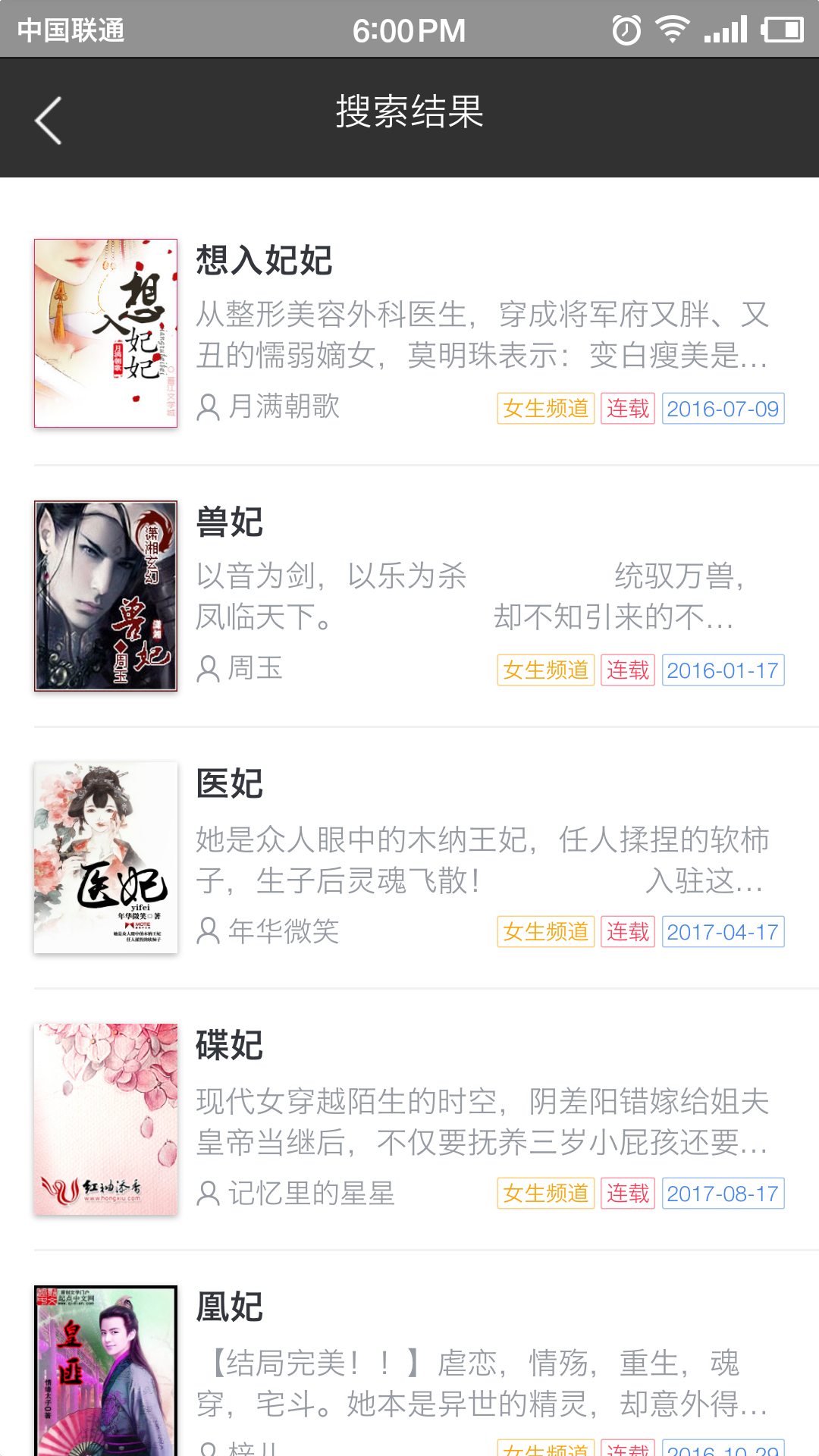
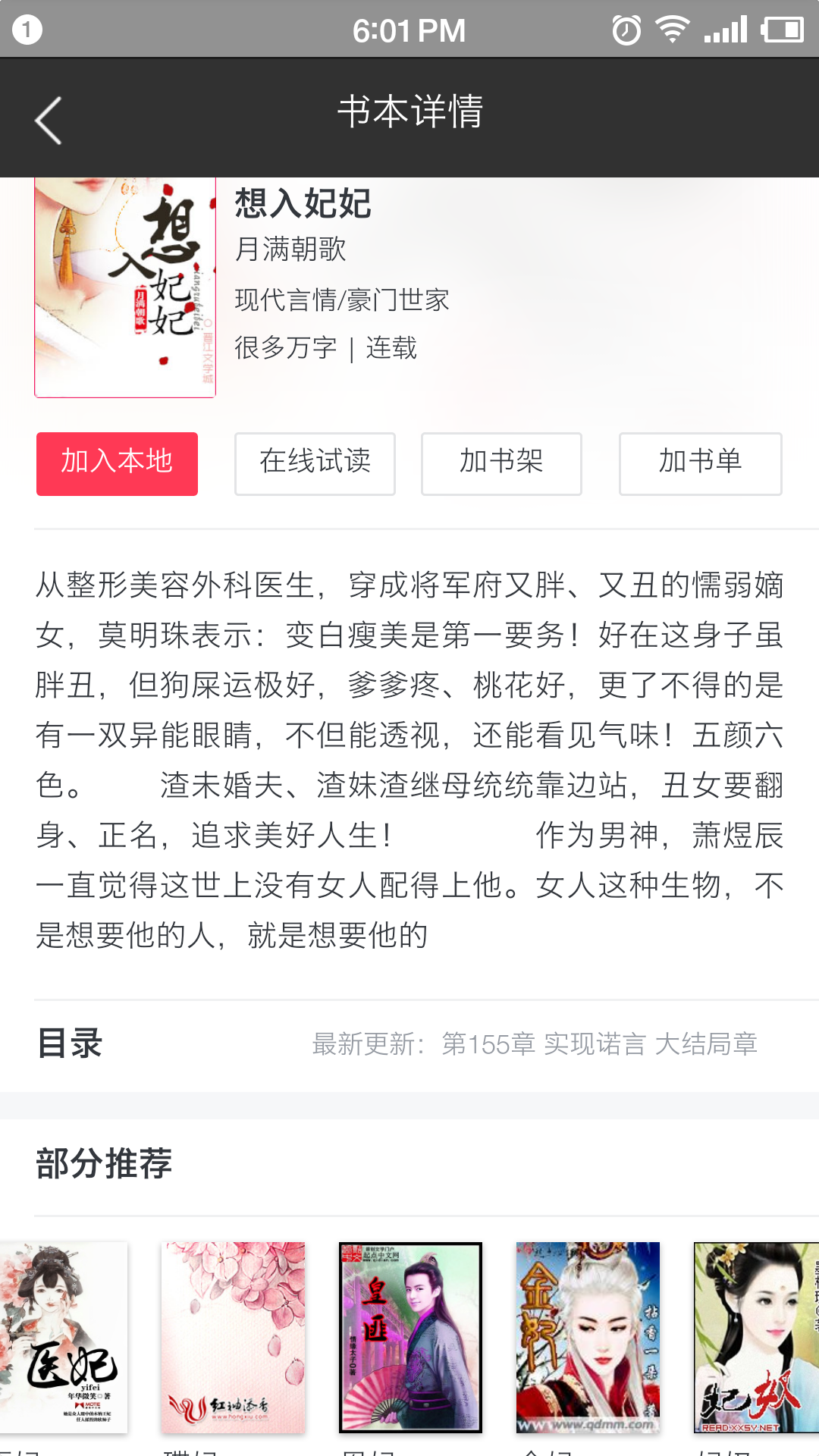



打赏本站,你说多少就多少

上一篇:linux服务器安装php环境
下一篇:【抓取网页】的一些注意事项